
AI - Driven Product Engineering
AI Product-Driven Engineering is an innovative approach that integrates artificial intelligence deeply into the product development lifecycle. It leverages machine learning, automation, and data-driven insights to accelerate design, optimize development processes, and enhance product quality.
AI Engineering Acceleration Metrics
76%
of organizations say AI-driven engineering has accelerated their product development cycles.
60%
of engineering tasks are expected to be automated by AI, freeing teams to focus more on innovation.
3-4X
faster time-to-market for companies that embed AI into their product engineering processes.
$15B
collective monthly investment by enterprises in AI tools, infrastructure, and engineering automation.
Why AI-Driven Product Engineering Matters
AI-driven product engineering empowers organizations to build smarter, faster, and more resilient products. By embedding AI into the engineering lifecycle, businesses can automate repetitive tasks, enhance decision-making with data-driven insights, and accelerate innovation. It enables predictive maintenance, optimizes design processes, and delivers personalized user experiences at scale. In a competitive market, AI-driven engineering isn’t just an advantage — it’s a necessity to stay agile, reduce costs, and bring cutting-edge products to market faster than ever.
Engineering Intelligence Surge
47%
of organizations cite a lack of skills and training as a top barrier to operationalizing multi‑cloud or hybrid‑cloud environments

Case studies and proof — AI-Driven Product Engineering
Curated case studies showing how AI embedded across the product lifecycle reduced time-to-market, automated engineering work, and delivered measurable business impact; below are the most relevant examples for this service and quick links to read the full case studies

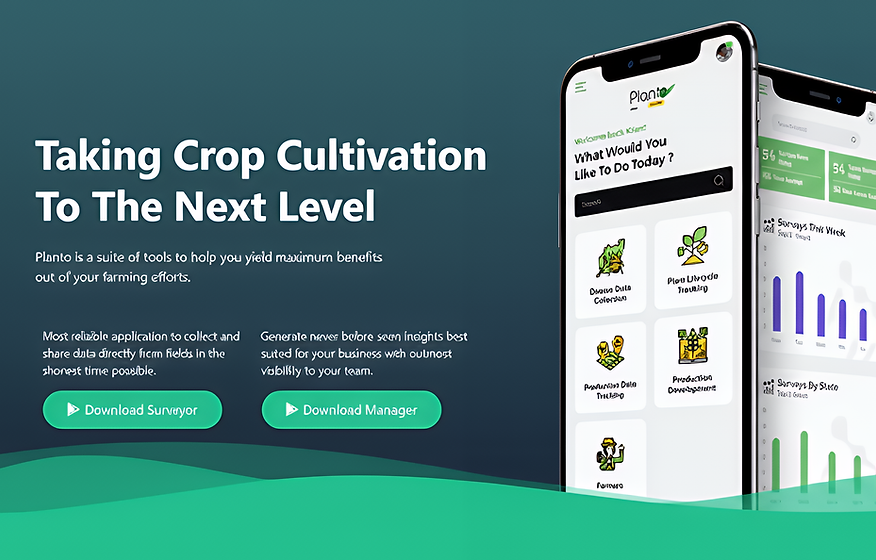
Seedvision
the product of a new age agritech company called Agdhi, which uses AI and computer vision-enabled patented technology to test seeds with their DNA sequence.
_1344x768_2688x1536.png)
_2688x1536.png)
Fleetnext
a powerful platform for tracking vehicles, analyzing critical data, setting alerts for urgent situations, and detecting faults before they escalate.
_2688x1536.png)
Thought leadership
AI is a product capability, not an add-on. Treat models like features: define hypotheses, measure outcomes, and bake retraining and governance into every release. When teams adopt model-centric product discipline, what often looks like “one-off automation” turns into a durable differentiation layer that continuously improves customer outcomes.
-
Build experiment-driven model loops: instrument decisions, rank candidate actions, run small hypothesis experiments, then feed results back into model training and product prioritization.
-
Design for reversibility and auditability: model rollouts must be easy to rollback, observable at the KPI level, and logged end-to-end so product managers can treat models the same way they treat UI changes.
Product ideas
Discover forward-looking product opportunities that extend the value of AI-driven engineering. These ideas are designed to inspire innovation by showing how data, models, and user experience can converge into market-ready capabilities. Each concept illustrates how AI can be embedded not just as a feature, but as a scalable product advantage.
The Hypothesis Engine is designed to transform raw data signals into actionable product experiments. By ingesting event telemetry, session replay logs, and direct user feedback, it builds a prioritized backlog of UX or feature changes directly tied to measurable KPIs such as conversion rate, churn reduction, or defect detection rate. Product managers can see which opportunities are most likely to deliver value, reducing the guesswork often involved in roadmap planning.
Beyond just idea generation, the system is built to support a closed-loop validation cycle. Each proposed hypothesis is linked with testable metrics, so experiments can be rapidly deployed, monitored, and iterated upon. As outcomes roll in, the engine learns which interventions have the greatest effect, feeding continuous improvement cycles. This ensures that models are not only producing insights but actively driving product evolution in a systematic and measurable way.
Model Canary Studio provides a dedicated platform for safe, controlled deployment of machine learning models into production. It enables teams to run canary experiments where traffic is split between the old and new versions of a model, allowing real-world performance to be measured under live conditions. The platform enforces automatic performance gates, alerting stakeholders if KPIs such as latency, accuracy, or business outcomes deviate beyond acceptable thresholds.
In addition, the studio is designed for speed and resilience. If drift or degradation is detected, automated rollback protocols ensure that problematic models are quickly removed from the critical path, minimizing risk. Teams gain confidence that new models can be iterated and tested continuously without endangering customer experience or business performance. This makes Model Canary Studio a key enabler of sustainable, reliable AI adoption in product pipelines.
The Privacy-First Personalization API enables businesses to deliver customized user experiences while maintaining strict compliance with privacy regulations. It enforces feature gating and differential exposure rules to ensure that personalization happens only with explicit user consent. Additionally, it creates detailed audit trails, documenting how and when personalization decisions were made, which strengthens transparency and regulatory defensibility.
Unlike black-box personalization systems, this API is designed with explainability and accountability in mind. By embedding consent-awareness directly into the inference pipeline, it prevents data misuse and builds user trust. At the same time, it allows product teams to deliver meaningful personalization that enhances engagement, retention, and satisfaction, without compromising on compliance obligations like GDPR or CCPA.
The Seed Quality Dashboard provides agritech companies and farmers with a unified platform to monitor, evaluate, and improve crop inputs. Field devices synchronize data with a centralized cloud analytics engine, which visualizes batch quality metrics and detects anomalies. By incorporating model confidence levels and batch comparisons, the dashboard provides an early warning system for potential seed quality issues before they affect yields.
The dashboard is not just descriptive but prescriptive. It includes sample management capabilities and retraining triggers, ensuring that predictive models are continuously updated with the latest field data. This reduces the lag between issue detection and corrective action. Over time, the dashboard evolves into a decision-support system, helping organizations optimize seed quality, reduce wastage, and improve agricultural sustainability.
The Hypothesis Engine is designed to transform raw data signals into actionable product experiments. By ingesting event telemetry, session replay logs, and direct user feedback, it builds a prioritized backlog of UX or feature changes directly tied to measurable KPIs such as conversion rate, churn reduction, or defect detection rate. Product managers can see which opportunities are most likely to deliver value, reducing the guesswork often involved in roadmap planning.
Beyond just idea generation, the system is built to support a closed-loop validation cycle. Each proposed hypothesis is linked with testable metrics, so experiments can be rapidly deployed, monitored, and iterated upon. As outcomes roll in, the engine learns which interventions have the greatest effect, feeding continuous improvement cycles. This ensures that models are not only producing insights but actively driving product evolution in a systematic and measurable way.
The Hypothesis Engine is designed to transform raw data signals into actionable product experiments. By ingesting event telemetry, session replay logs, and direct user feedback, it builds a prioritized backlog of UX or feature changes directly tied to measurable KPIs such as conversion rate, churn reduction, or defect detection rate. Product managers can see which opportunities are most likely to deliver value, reducing the guesswork often involved in roadmap planning.
Beyond just idea generation, the system is built to support a closed-loop validation cycle. Each proposed hypothesis is linked with testable metrics, so experiments can be rapidly deployed, monitored, and iterated upon. As outcomes roll in, the engine learns which interventions have the greatest effect, feeding continuous improvement cycles. This ensures that models are not only producing insights but actively driving product evolution in a systematic and measurable way.
Solution ideas
Explore proven implementation patterns that translate vision into execution. These solution frameworks outline the technology stack, operational approach, and key performance outcomes needed to deliver measurable business impact. They serve as practical blueprints for teams to reduce risk, accelerate delivery, and scale AI responsibly.
Solution Idea | Detailed Description |
|---|---|
Operational & Governance Checklist | - Log inputs, model decisions, and confidence bands by default.
- Gate rollouts by business KPIs, not just technical metrics.
- Maintain fast rollback paths and assign clear ownership (Product + ML engineer).
- Automate data-sanity checks and synthetic scenario tests in CI.
- Prioritize explainability for customer-facing decisions with audit trails + human-readable rationale. |
Human-In-The-Loop (HITL) Safety Gate (for high-impact domains: insurance, finance) | Stack: Decision logging → confidence band thresholds → human review queue UI → feedback routed to training data store → automated retrain triggers.
KPI Targets: Manual review rate <10% of transactions; accuracy uplift on retrain +5–8%.
Why it Wins: Adds a structured human checkpoint where incorrect automation could be costly, reducing risk and improving trust in model-driven systems. |
Edge/Cloud Hybrid Inference Pattern (for low-latency IoT & agritech) | Stack: Quantized models on edge devices → periodic sync to cloud re-ranker → feature-store sync (eventual consistency) → per-request cost metering.
KPI Targets: Median latency <50 ms for edge-critical requests; inference cost per 1k requests reduced by 30%.
Why it Wins: Achieves the right trade-off between speed and cost, keeping critical scoring local while enriching decisions with cloud context where necessary. |
ModelOps Production Blueprint (for safe model shipping) | Stack: Git-packaged model artifacts → reproducible build (containers + metadata) → automated validation jobs (unit tests, data-sanity checks, synthetic scenarios) → CI/CD for models → canary/blue-green orchestrator → monitoring (latency, drift, KPI-backed SLOs).
KPI Targets: Rollback time <15 minutes; canary failure rate <2%.
Why it Wins: Reduces human error, enforces reproducibility, and ensures business KPIs are the primary deployment signals, not just raw model metrics. |
Variant Recommendation Pipeline (for product experiments) | Stack: Analytics event stream (Kafka) → session replay store → feature store → causal-ranking model (TF/PyTorch) → UX vetting UI → feature-flag rollout (LaunchDarkly/homegrown).
KPI Targets: Increase experiments/month by 3×; median experiment cycle <2 weeks.
Why it Wins: Creates a closed-loop pipeline that ties data → model → UX, turning product hypotheses into measurable, automatable experiments. |